Amazon Ontrac (Ratings or Reviews or Complaints or Evaluation)
DS in Existent World
Product Recommender using Amazon Review dataset
What is the Problem? Why practice we need Recommender Systems?
Online stores have millions of products bachelor in their catalogs. Finding the right product becomes difficult considering of this 'Information overload'. Users get confused and this puts a cerebral overload on the user in choosing a production.
What are recommender systems?
Recommender systems help customers by suggesting probable list of products from which they can easily select the correct one. They make customers aware of new and/or similar products available for buy by providing comparable costs, features, delivery times etc.
Recommender systems take become an integral part of due east-commerce sites and other businesses like social networking, movie/music rendering sites. They have a huge impact on the acquirement earned by these businesses and also benefit users past reducing the cognitive load of searching and sifting through an overload of information. Recommender systems personalize client experience past understanding their usage of the system and recommending items they would find useful.
You might have come across examples like below for amazon recommendation arrangement:
Recommender systems can be built with two different methods: Content Based Filtering, and Collaborative Filtering.
Content Based Filtering
In content-based filtering, the similarity between different products is calculated on the footing of the attributes of the products. For instance, in a content-based volume recommender system, the similarity between the books is calculated on the ground of genres, the writer of the volume, the publisher of the volume, title of the volume etc.
Collaborative filtering
Collaborative filtering is commonly used for recommender systems. These techniques aim to fill in the missing entries of a user-particular association matrix. We are going to apply collaborative filtering (CF) approach.
CF is based on the idea that the best recommendations come from people who accept similar tastes. In other words, it uses historical item ratings of like-minded people to predict how someone would rate an detail.Collaborative filtering has two sub-categories that are generally called memory based and model-based approaches.
Retentiveness-based
There are 2 approaches: the first one identifies clusters of users and utilizes the interactions of one specific user to predict the interactions of other similar users. The 2nd approach identifies clusters of items that take been rated by user A and utilizes them to predict the interaction of user A with a unlike but similar detail B. These methods usually run into major problems with big sparse matrices, since the number of user-item interactions can be besides depression for generating high quality clusters.
Model-based
These methods are based on machine learning and data mining techniques. The goal is to train models to be able to make predictions. For example, we could use existing user-particular interactions to train a model to predict the top-v items that a user might similar the most. 1 advantage of these methods is that they are able to recommend a larger number of items to a larger number of users, compared to other methods like memory based approach. They have large coverage, even when working with large sparse matrices. [10]
Matrix factorization
A very popular collaborative filtering method is matrix factorization. It has a set up of users and a ready of items, and a very sparse matrix that represents known user-to-item ratings. We want to predict missing values in this matrix. In order to practise this, we represent each user and each detail as a vector of latent features, such that dot products of these vectors closely match known user-to-item ratings. The expectation is that unknown user-to-particular ratings can be approximated past dot products of respective feature vectors as well. The simplest form of objective function, which we want to minimize, is:
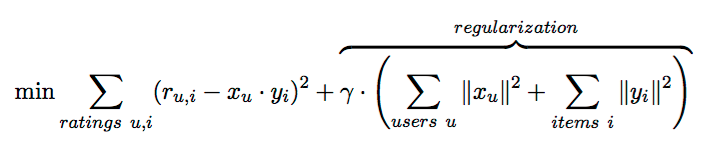
Here, r are known user-to-item ratings, and 10 and y are the user and item feature vectors that we are trying to find. As there are many free parameters, we demand the regularization role to prevent overfitting and numerical problems, with gamma beingness the regularization factor. After some number of iterations, changes in feature vectors become very small, and convergence is reached.
Alternating to the lowest degree square
Alternating least foursquare (ALS) is 1 of the methods for Matrix factorization. It is used with nonlinear regression models, when there are two dependent variables (in our case, vectors x and y). The algorithm fixes one of the parameters (user vectors x), while optimally solving for the other (item vectors y) by minimizing the quadratic form. The algorithm alternates betwixt fixing user vectors and updating particular vectors, and fixing detail vectors and updating user vectors, until the convergence criteria are satisfied.
There are several efficient and scalable implementations of Matrix Factorization in the manufacture. Amid them, a prominent one is that provided by Apache Spark, a distributed data-processing engine that can exist run easily on Amazon Web Services with an Elastic Mapreduce cluster.
Apache Spark implements a distributed version of the Alternating To the lowest degree Square (ALS) method with Weight Regularization.
Data acquisition and selection
The dataset is available on the UCSD website. Thanks to Professor McAuley and team for making this dataset available. [ane][2] This dataset contains production reviews and metadata from Amazon, including 142.eight 1000000 reviews spanning May 1996 — July 2014. [1] Considering of the vast size of the data, information technology is quite a claiming to handle it all. So the recommender is built using datasets of 5 product categories namely Patio, backyard and garden , Musical instruments, Office products, Automotive, Instant video.
Data cleaning
To bring the data into a consequent format, steps taken are:
- Drop unnecessary columns
- Driblet duplicate records
- Check for invalid data
- Bank check ranges for applicable columns (such as ratings betwixt i and five)
- Bargain with missing values and outliers
Exploratory Information Analysis
It's skillful do to know the features and their data types and to have a look at the data distribution. Plotting the information tin can provide insights into the patterns that the information follows. 'Patio, Lawn & Garden' production category dataset is used for plotting graphs 1 to 6.
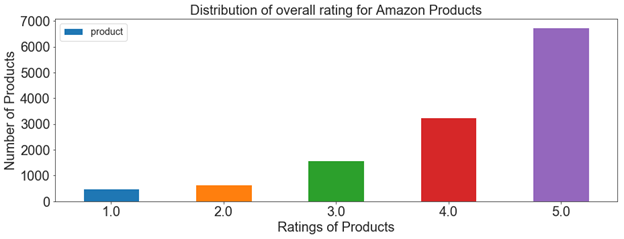
1)Distribution of overall product ratings
Many users have given a rating of 5 to products followed by four and iii whereas very few users have given a low rating of i or 2.
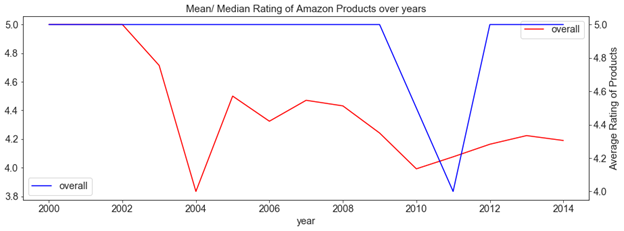
2) Mean and median of ratings over years
Looking at beneath plot, we tin can infer that over the years 2000 to 2014, the mean rating of the products has reduced. Median of ratings given to products remains at v from 2000 to 2014 except for years 2010 and 2011
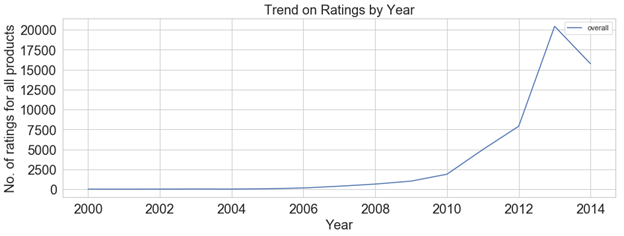
3) Trend of number of ratings across years
At that place is an increasing trend for number of ratings given by the users to products on Amazon which indicates that a greater number of users started using the Amazon east-commerce site for online shopping and a greater number of users started giving feedback on the products purchased from 2000 to 2014. There is a significant increase in number of ratings given by users from 2012 to 2014.
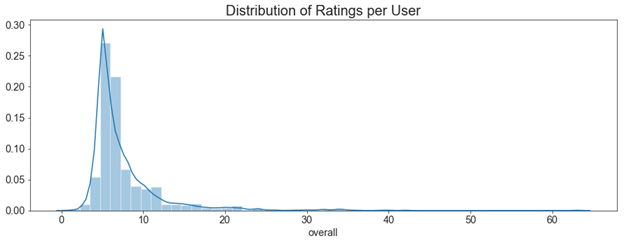
four) Distribution of ratings per user
Distribution of ratings per user shows a long-tail normal distribution. Full number of users in Garden and Patio dataset is 1685. Maximum number of ratings given by single user is 63 and minimum number of ratings by single user is i. On an average a user gives 7.55 ratings on Amazon as per the information present (till 2014).
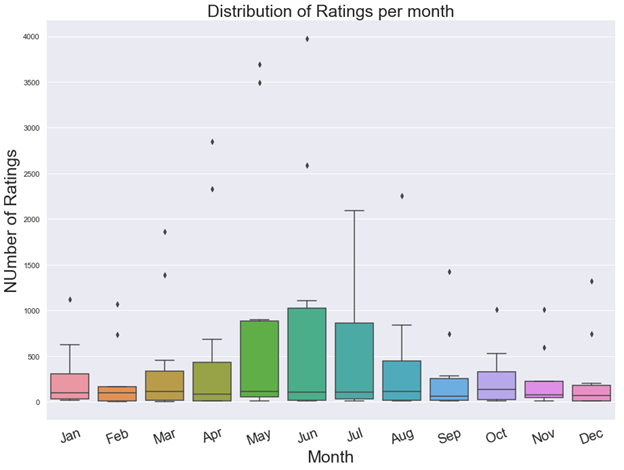
five) Distribution of ratings past month
From the box plot below, we can say that highest number of ratings are given in the month of June followed past May and July. Information technology indicates that in these three months, there is a high book of purchases. As against that, February shows the lowest number of ratings given past users so one tin infer that lowest sales might have happened in the month of February. This makes sense considering in summer months there is a higher purchasing of gardening products.
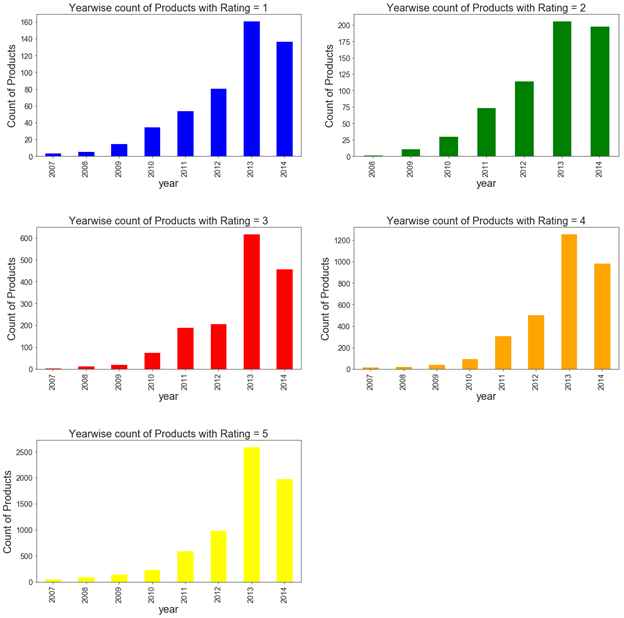
6) Year wise count of Amazon products with particular rating
Below plot shows that number of products with ratings '1', '2' or '3' is significantly less over the years as compared to those with ratings 'four' and '5'.
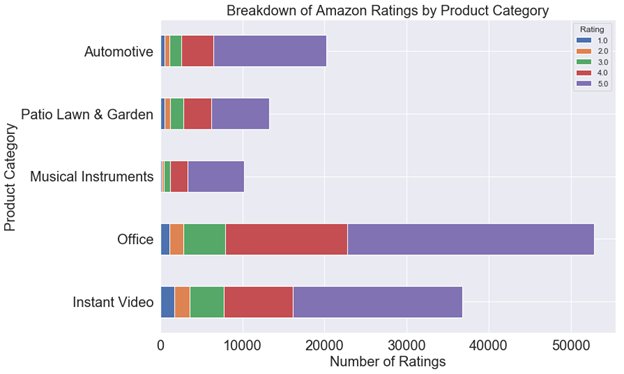
7) Breakdown of Amazon ratings by product category
I have used 5 different datasets from Amazon review dataset to plot below chart namely 'Automotive', 'Garden and Patio', 'Musical Instruments', 'Role' and 'Instant Video'. In general, 'Office category' products and 'Instant Video' seem to be more than popular in these 5 categories. In all five categories, number of good ratings(4,5) is more than than number of bad ratings (ane,ii).
Implementation
Spark prepare
I have installed Spark on a Windows 10 machine with 32 GB RAM Intel i5 processor.
Spark MLLib
ALS implementation provided by Apache Spark MLlib is used for this recommender. MLlib is Apache Spark's scalable car learning library. Spark excels at iterative computation, enabling MLlib to run fast.
Apache Spark implements a distributed version of the Alternate To the lowest degree Square (ALS) method with Weight Regularization. Apache'south spark.mllib currently supports model-based collaborative filtering, in which users and products are described by a small set of latent factors that can be used to predict missing entries. spark.mllib uses the alternate to the lowest degree squares (ALS) algorithm to larn these latent factors. [6] [12]
Model option and hyper-parameters
Main hyper parameters set for the recommendation engine are rank (number of latent factors), lambda (regularization parameter) and iterations. Rank was set with values [eight, 10, 20] for [0.6,0.2,0.2] split and was [ 2,five,10,20] for no split in dataset. Lambda used ranges from [0.001 to 50]. Iterations vary between five and 20 for no carve up in dataset and are set to 20 for [0.6,0.2,0.two] split in dataset.
I accept used ALS implementation from spark.mllib where these hyper-parameters can be set and tested.
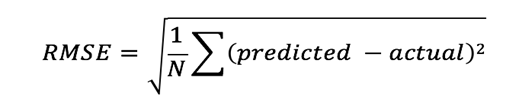
Model Evaluation
For recommendation engine evaluation, different metrics like RMSE, MAE, Precision and think are used. I have used RMSE for the model evaluation. Lesser the RMSE, better is the recommendation engine.
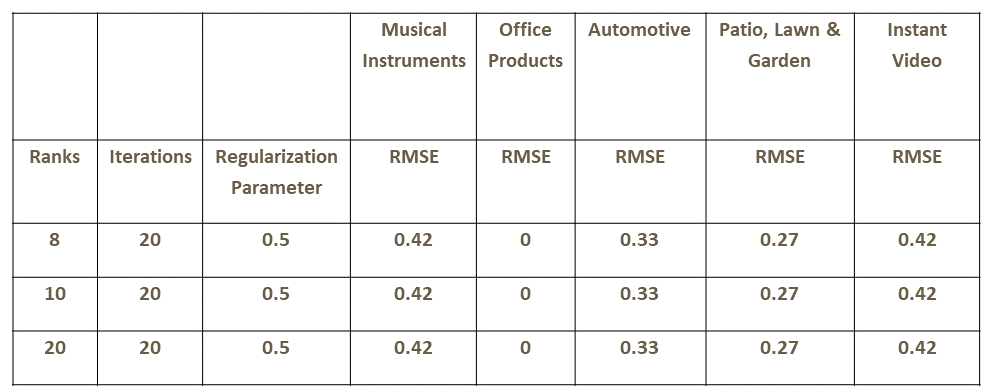
Results
1)The dataset was split into training, testing and validation as preparation — 60%, testing -20% and validation — twenty%. In addition to using the split, nosotros vary the rank hyper-parameter in the range 8–20. A few key observations are as follows:
- We consistently see low RMSE values for all categories evaluated here.
- Rather surprisingly, the RMSE for the office supplies category is 0, indicating perfect predictions (nosotros checked the data for bugs or systematic problems like all null or same values but did not notice any issues).
We see very little or no sensitivity of the metric to the rank hyper-parameter. A search in a bigger range for this parameter would be an interesting next footstep.
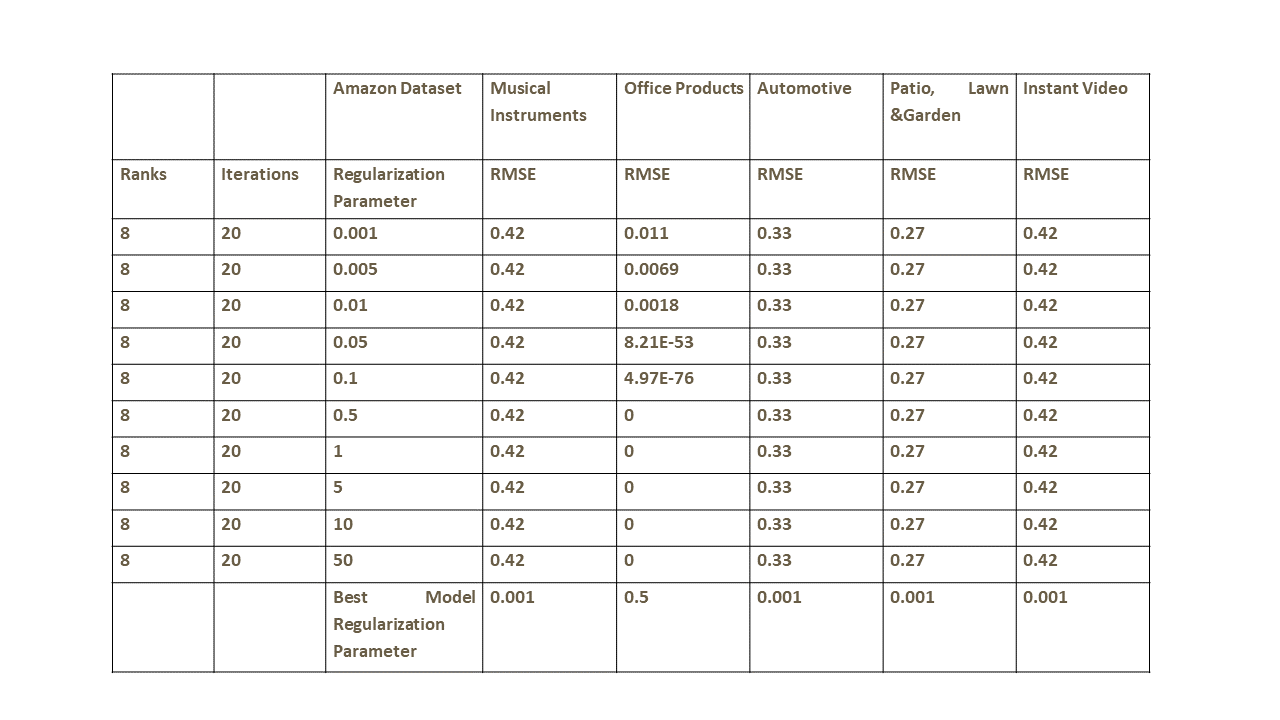
2) In the 2nd method, nosotros use a 60–20–20 split for train, validation and exam prepare once more. In addition to using the dissever, we vary the regularization hyper-parameter in the range 0.001–50. A few key observations are as follows:
a) For all production categories except 'Function production' category, setting regularization parameter equal to 0.001 gives best RMSE. For 'Office product' category regularization parameter of 0.five and above gives best RMSE.
b) We run into very little or no sensitivity of the metric to the regularization hyper-parameter except in case of Office production category.
Decision
In this article, we accept discussed a product recommender with five different product categories from Amazon review dataset built using Apache PySpark MLLib and have discussed major steps involved in edifice a recommender as a information science projection.
Next Steps
We would similar to implement this recommender in cloud. Customizing the recommender for remaining product categories in Amazon Review dataset would be the next stride. This recommender makes utilize of ratings given by users. Making apply of review text given by users would be interesting as a further step.
Acknowledgement
I sincerely thank my data scientific discipline mentor -Dr. Ramakrishna Soma for his guidance and encouragement to complete this project.
References
one) R. He, J. McAuley, Ups and downs: Modeling the visual evolution of fashion trends with one-course collaborative filtering, WWW, 2016 pdf
2) J. McAuley, C. Targett, J. Shi, A. van den Hengel, Paradigm-based recommendations on styles and substitutes, SIGIR, 2015, pdf
3) The Good, Bad and Ugly: Apache Spark for Information Science Work
https://thenewstack.io/the-good-bad-and-ugly-apache-spark-for-information-science-work/
4) Pythonic Information Cleaning With NumPy and Pandas
https://realpython.com/python-data-cleaning-numpy-pandas/
5) Data Cleaning with Python and Pandas: Detecting Missing Values
https://towardsdatascience.com/data-cleaning-with-python-and-pandas-detecting-missing-values-3e9c6ebcf78b
6) Apache Spark https://spark.apache.org/
7) Apache PySpark
https://spark.apache.org/docs/0.9.one/python-programming-guide.html
8) J.Bobadilla, F.OrtegaA., HernandoA.Gutiérrez, Recommender systems survey in Knowledge-Based Systems, Volume 46, July 2013, Pages 109–132
ix) What is Collaborative Filtering?
https://dzone.com/articles/building-sales-recommendation-engine-with-apache-due south
ten) Charu C. Aggarwal, Recommender Systems, a comprehensive book
eleven) Greg Linden, Brent Smith, Jeremy York, Amazon.com Recommendations: Detail-to-Item Collaborative Filtering, IEEE Internet Computing, five.7 n.one, p.76–80, January 2003
12) Apache Spark — ALS
https://spark.apache.org/docs/two.two.0/ml-collaborative-filtering.html
13) Simple Matrix Factorization example on the Movielens dataset using Pyspark
https://medium.com/@connectwithghosh/simple-matrix-factorization-case-on-the-movielens-dataset-using-pyspark-9b7e3f567536
Source: https://towardsdatascience.com/product-recommender-using-amazon-review-dataset-e69d479d81dd
0 Response to "Amazon Ontrac (Ratings or Reviews or Complaints or Evaluation)"
Postar um comentário